Devoxx 🇫🇷 2023
J’ai eu la chance de participer pour la première fois à DevoxxFR (édition 2023) et même d’y donner une conférence, mais nous y reviendrons dans un second temps. Pour les non-informaticiens, Devoxx est un évènement payant de plusieurs jours, organisé par une association, regroupant des milliers de personnes gravitant autour de ce monde (développeurs, designers, experts d’une technologie ou d’une autre). Pendant ces trois jours, un ensemble de stands permet aussi aux entreprises partenaires de se faire connaître. Mais c’est surtout plus de 200 conférences dans une dizaine de salles, sous différents formats (long, court, avec travaux pratiques).
Embarquez avec moi jusque dans les coulisses de Devoxx France.

Disclaimer: les avis, remarques et sentiments exprimés dans cet article sont personnels et je tiens à féliciter tous les speakers de Devoxx. Ce n’est pas un exercice facile et une conférence peut plaire à certains et moins à d’autres.
Vous trouverez après chaque bloc un lien vers la vidéo Youtube 📹 de la conférence en question. Pour vous faire votre propre avis.
Cet article est publié des mois après la conférence, surtout comme notes pour moi-même.
Jeudi 13 Avril
Je n’ai pas pu participer à la journée de Mercredi, donc commençons directement par le 2ème jour 😊
Keynotes
Je ne vais pas commenter en détails les Keynotes, au nombre de 3 ce jeudi. Ce sont des conférences plus généralistes, qui éveillent souvent la curiosité sur un sujet plus ou moins lié à l’informatique. Lors des Keynotes, la plus grande salle (Amphi Bleu) est pleine et la conférence est rediffusée dans 3-4 autre salles pour permettre à tous les participants d’y assister.
Céline LAZORTHES nous a parlé de l’impact positif de l’informatique (et notamment l’intelligence artificielle) dans le domaine de la médecine, et notamment la détection plus rapide de maladies et de cancers. Belle mise en pespective qui nous rapelle que nous sommes tous humains et que nous pouvons choisir pour quel domaine travailler (militaire, médical, …)
Philippe BIHOUIX est ensuite monté sur scène pour faire un lien entre développement et développement durable 🙂 Il a challengé nos habitudes numériques et rappelé quelques chiffres et faits marquants qui font réfléchir sur notre consommation quotidienne.
Je n’ai pas assisté à la 3ème Keynote pour faire un tour des stands mais j’ai eu quelques retours sur le fait qu’elle était un peu hors sujet.
10h45 – 11h15 (Amphi Bleu) : L’IA va-t-elle changer notre métier de développeur ?
Speaker : Eric GRENON / Louis-Guillaume MORAND Microsoft France
Après un rapide rappel du concept d’Intelligence Artificielle et de la différence entre création et innovation, les speakeurs nous expliquent en quoi le prompt est une rupture dans la façon de communiquer avec l’IA (en reprenant le contrôle sur la machine).
Ensuite, un zoom est fait sur Copilot de Github (et donc de Microsoft) à travers une démonstration :
- Génération de code (dans différents langages et contextes)
- Refactoring de code (la démonstration a échoué car Copilot a simplifié le code en le supprimant !!!)
- Traduction de code d’un langage à un autre (impressionnant)
- Explication de code (par bloc et en tenant compte du contexte)
- Discussion avec questions/réponses et propositions de corrections
- Génération de code mais avec un chat de discussion
S’ensuivent quelques retours de développeurs utilisant Github Copilot: « Cela réduit le temps passé à coder, réduit la charge mentale et augmente la concentration« .
Une question me vient à l’esprit (que je n’ai pas pu poser): « Est-ce que la qualité de code ne va pas globalement baisser, les développeurs étant assistés par une IA qui a appris de code généraliste ? »
Je pense que ce genre d’outil peut être très intéressant pour analyser et refactorer du code legacy.

11h45 – 12h20 (Salle 252) : Le cache HTTP
Speaker : Hubert SABLONNIERE Clever Cloud
Hubert Sablonniere est une référence de très bon speaker pour moi depuis plusieurs années (Lemmings Power). Je trouve ses présentations très claires, avec la bonne dose d’humour, des exemples parlants et surtout une vulgarisation toujours au bon niveau 👏
Je ne rate donc pas une occasion comme celle-ci d’aller assister à une nouvelle conférence, aujourd’hui sur le sujet du cache HTTP.

En suivant le plan du métro, il déroule la RFC 9111 et toutes les possibilités des headers de cache HTTP.
Chaque propriété et son utilisation sont illustrées par un exemple avec des petits chats 🐈 Et on remarque que les navigateurs fonctionnent différemment, que le cache peut être à différents niveaux (CDN, navigateur, …)
Si c’est un sujet qui vous intéresse ou que vous êtes amenés à optimiser un site avec du cache, regardez cette conférence et prenez des notes.
Mention spéciale au header cache-control: no-cache
Le code des exemples est disponible ici : https://github.com/hsablonniere/talk-back-to-basics-cache/tree/devoxx
13h – 13h15 (Amphi Maillot) : Tous architectes
Speaker : Simon MAURIN Leboncoin
C’est un des mantras de l’équipe d’architectes chez ManoMano : « Tout le monde fait de l’architecture » alors ce talk a forcément attisé ma curiosité.
En retraçant l’évolution de l’entreprise LeBonCoin et de son organisation autour de l’architecture, Simon nous explique les différentes problématiques rencontrées et les solutions mises en place pour y palier.
Je retiendrai deux choses:
- « Obtenir le consentement (personne n’est contre) plutôt que le consensus (tout le monde est d’accord) ». C’est vrai avec une taille d’entreprise grossissante, il est parfois difficile de prendre des décisions.
- Ecrivez des Architecture Decision Records mais rendez-lez visibles et accessibles.
Une image pour résumer la très bonne présentation de Simon

13h30 – 14h15 (Amphi Bleu) : Loi de Conway
Speaker : Julien Topçu Shodo
Très difficile de résumer ce talk tellement il contenait d’informations intéressantes.
Après une introduction un peu longue (mais très à propos) sur le cabinet McKinsey, Julien nous parle de la Loi de Conway
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
Melvin E. Conway
En prenant des exemples (comme le cabinet McKinsey ou Windows Vista), cette loi devient plus claire. Mais comment éviter de tomber dans ce piège, surtout dans les grandes organisations ?
Le modèle BAPO remet les choses dans l’ordre en ne subissant pas l’organisation mais en l’adaptant pour répondre aux besoins Business.
Stratégie Business / Produit → Architecture → Process et fonctionnements → Structure Organizationelle
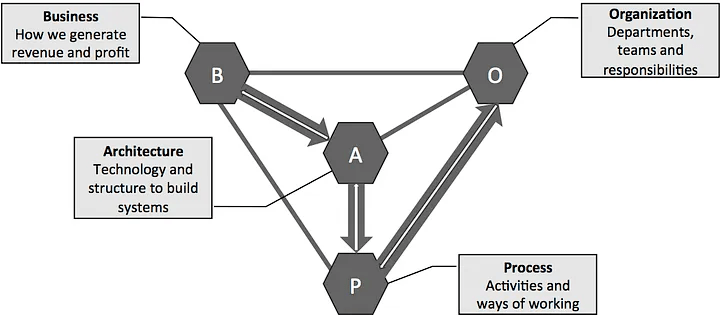
Très intéressant. Je vais chercher un retour d’expérience d’entreprise qui aurait mis en place ce modèle 🤔
14h30 – 15h15 (Maillot) : 5 ans de bien et de moins bien avec Kafka
Speaker : Nelson DIONISI – Matthieu MOUMINOUX Mirakl
Mirakl a commencé à travailler assez tôt avec Apache Kafka (en 2016) et avec une contrainte forte : faire du multi-tenant pour gérer ses multiples clients.
Neslon et Matthieu nous expliquent leur parcours avec les différentes options mises en places et leurs problèmes. C’est intéressant car nous rencontrons les mêmes soucis et la même évolution chez ManoMano.
Trop de topics, tous les évènements dans les mêmes topics, clients ralentis par d’autres, perte de messages, trop de messages. Voici tous les problèmes rencontrés et comment les résoudre.
Une partie intéressante concernant l’industrialisation (via une libraire commune) montre la puissance de mutualiser/abstraire certaines complexités techniques.
Malheuresement, je n’ai pas pu assister à la fin du talk.
Mon talk – Gestion de la dette d’architecture dans un contexte d’hypercroissance
J’ai donc dû quitter un peu avant la fin la conférence précédente pour me préparer à donner la mienne. Mon rythme cardiaque augmente, mais je me pose pour bien respirer, faire de la visualisation mentale et le stress redescend. J’ai déjà eu l’occassion de donner ce talk à Bordeaux devant une salle de 600/700 personnes, mais là, c’est Devoxx et dans la plus grande salle.
Je rentre dans l’Amphi Bleu et monte sur scène. Ah suprise, mon nouveau Mac ne permet pas de diffuser sur plus de 2 écrans… J’aurai donc mes notes sur mon portable et le reste sera projeté derrière moi, impossible de me déplacer trop loin du pupitre.
Je déroule mes slides et essaye de donner du dynamisme dans mon ton et mes phrases. A mi-parcours, je confonds mon timer (temps passé) et celui de l’organisation (temps restant) et je pense que j’ai largement le temps.
Mais les slides passent et la fin se rapproche, j’accélère donc et finis sur le fil (avec quelques secondes de retard). Il n’y aura pas de questions et je trouve ça dommage.
J’ai répété de nombreuses fois mon talk mais j’ai tendance à parler plus sur scène, pour être sûr que mon propos est compris par tous. Dommage pour cette fois.
Quelques personnes sont venues échanger à la fin, partageant les mêmes problématiques, avec des approches similaires ou différentes. Très enrichissant.
Ça fait quand même une belle photo souvenir pour mon anniversaire 😊

16h45 – 17h30 (AB) : Démystifions Kubernetes
Speaker : Denis Germain Deezer
J’ai ensuite enchainé avec une introduction à Kubernetes par notre ami bordelais Denis Germain.
C’est un outil que j’utilise au quotidien professionnellement mais je ne connais que les concepts principaux, sans avoir jamais mis le nez dans la partie technique (et ce n’est pas mon domaine du tout).
Denis nous a expliqué les principaux composants nécessaires (natifs ou non) pour démarrer un cluster :
- Control Plane
- ETCD = Database
- Controller = Connecté à l’API server pour manager les pods + nodes
- Scheduler = démarre les pods et gère leur nombre
- Kubelet = agent sur les workers pour donner les informations (pods/cpu) + contrôler runtime
- CNI plugin = implémentation du réseau
- Ingress Controller = HTTP routeur (comme Traefik)
C’était clair et les étapes de démonstration permettent de mieux se rendre compte de la simplicité et des dépendances.
La démo et les slides sont disponibles sur github https://github.com/zwindler/demystifions-kubernetes
Vendredi
Après une soirée moins studieuse (concert, repas, alcool et longues discussions), j’ai un peu trop profité de mon lit au calme ce matin et je suis arrivé au Palais des Congrès vers 09h30.
J’ai pu assister à la Keynote de Marion POITEVIN, première femme française dans un groupe d’élite d’alpinisme de l’armée de terre. Elle explique le plafond de glace (métaphore du plafond de verre) qu’elle a rencontré en tant que femme dans ce domaine d’élite qu’est l’alpinisme de haut niveau. Son talk était très inspirant et donne envie de lire son livre : Briser le plafond de glace

10h45 – 11h30 (251) : IPFS
Speaker: Cody Zuschlag Nearform
Je pensais que ce talk en anglais était un talk technique sur l’utilisation d’IPFS avec des démonstrations. Ayant un peu utilisé ce protocole pour tester les NFTs, je pensais voir des cas d’usage plus pratiques et professionnels.
Mais le talk était vraiment une introduction à cette technologie, expliquant le concept de base.
IPFS pour Internet Planetary File System est un système de stockage de fichiers décentralisé basé sur la blockchain. Il peut servir pour héberger des sites, distribuer des paquets/librairies, dans le gaming ou encore dans le monde de la crypto.
Pour ceux qui veulent explorer la technologie, je vous conseille ce très bon article : https://thebidouilleur.xyz/blog/ipfs/
https://www.youtube.com/watch?v=kQOkTet31gY
11h45 – 12h30 (252) : Avoir de l’impact en tant qu’Engineering Manager
Speaker : Dimitri Baeli / Benoit Guillon BackMarket / Malt
Dans mon entreprise (ManoMano), un Engineering Manager est un manager technique responsable de 3-4 équipes. C’est un rôle que je trouve intéressant, car il mêle management et expertise technique sur de nombreux sujets (langages, infrastructure, architecture, etc). Je suis donc venu assister à ce talk pour en tirer quelques retours d’expérience.
Mais à l’extérieur de ManoMano, un Engineering Manager est un Tech Lead (ou Chef de Projet Technique), responsable technique d’une équipe de 4 à 8 personnes.
Dimitri et Benoît ont premièrement décrit le rôle d’un EM en précisant 4 points:
- assurer une bonne vitesse de livraison tout en conservant la qualité attendue
- améliorer les résultats business
- contribuer à la culture de l’entreprise
- apporter de l’innovation et de l’intérêt
Pour pouvoir agir au mieux, ils doivent mesurer. A court terme avec les DORA Metrics et le Team Health Check ( de Spotify) et à long terme avec les approches Kaizen (amélioration continue) et Kaikaku (changements radicaux).
Les changements doivent être faits un par un pour mesurer l’impact et tout en respectant la maturité de l’équipe (niveau d’expertise, expérience).
La dernière partie sur le management humain était très intéressante, avec des conseils évidents mais pas toujours appliqués comme le fait de manager les gens comme des humains (en les écoutant, leur demandant comment ça va, en cherchant la diversité et en laissant les gens partir).
Enfin, ils conseillent aux Engineering Manager d’agir comme des DNS (pour aiguiller vers les bonnes personnes) plutôt que comme des Gateways (qui filtrent tout et bloquent les communicatinos transverses). Belle comparaison.

https://www.youtube.com/watch?v=4ekJwOV45ro
13h30 – 14h15 (Maillot) : Je malmène ta prod en direct avec 15 failles de sécu
Speaker: Gaëtan Eleouet Meritis
Première phrase « Les développeurs doivent être impliqués dans la sécurisation de leur application ». En effet, 72% des failles de sécurité proviennent de code applicatif.
J’ai un master en Sécurité Informatique (même si ce n’est plus mon métier) et je garde toujours un oeil sur ce domaine en faisant un peu de veille. Et cette conférence était plutôt destinée à des développeurs novices dans ce domaine.
Gaëtan propose à travers une application Qui aime quoi ? de parcourir les failles principales remontées par OWASP (organisme qui classifie les failles selon leur importance). C’est ludique et pédagogique.

Je vous mets ici la liste des failles abordées :
- CWE-209 Hide sensitive information
- CWE-89 SQL Injection
- CWE-352 CSRF (request from another website stealilng cookie)
- CWE-639 IDOR (access to data from another user)
- CWE-602 Always validate data in backend part
- CWE-565 Cookie data integrity (signature)
- CWE-915 Control fields you can modify during deserialization
- CWE-80 XSS Allow <script> in content executed by other user
- CWE-640 Light way to get forgotten password
- CWE-330 Random not enough random (CSPRNG)
- CWE-1352 Not up to date libraries
- CWE-841 Workflow step validation #cort
- CWE-419 Admin part accessible from Internet (VPN, IP restricted)
- CWE-288 Authentication not checked on all pages
- CWE-918 SSRF (Server calls himself URL)
- CWE-778 Log security/sensitive events
https://cheatsheetseries.owasp.org/
https://www.youtube.com/watch?v=Z0rgGrJLt-0
14h30 – 15h15 (AB) : Profitez de PostgreSQL pour passer à la vitesse supérieure
Speaker: Emmanuel Remy Casden

Ce talk présente comment utiliser PostgreSQL pour améliorer les performances et explorer diverses fonctionnalités, notamment la manipulation de types de données spécifiques, la génération de séries de données, la création de tables partitionnées, et le sharding.
Je suis utilisateur de PostgreSQL et connaissais déjà quelques fonctionnalités mais j’ai été bluffé par tout ce qui était disponible.
Je ne reviendrai pas sur la partie stockage de données particulières (géospatiales, composite, …), ni sur le sharding que j’ai déjà utilisés.
Saviez-vous que vous pouvez générer des suites de données grâce à quelques commandes PgSQL ?
J’ai aussi apprécié les fonctionnalités de sécurisation et d’anonymisation (comme le caractère SECURE sur une colonne qui anonymise automatiquemen tous les SELECT).
Nous avons ensuie découvert quelques bizarreries de PostgreSQL, comme le fait de supporter des fonctions en Python/NodeJS et autres languages. Ou le fait de connecter notre base de données à des services externes. Oui, vous avez bien lu. PostgreSQL est capable de wrapper des connexions à S3, des APIs REST ou à des fichiers (voir liste ici).
Ce sont bien évidemment des patterns que nous ne recommendons pas en Architecture mais qui existent.
Enfin, Emmanuel est revenu sur l’utilisation de JSONB, ses performances et capacités. C’est quelque chose que nous faisons de plus en plus dans mon entreprise.
Très bonne conférence pour toute personne qui travaille avec PostgreSQL.
https://www.youtube.com/watch?v=Zfdx2URaEOk
15h30 – 16h15 (252) : Ré-architecturer vos traitements batchs avec DDD
Speaker: Dorra BARTAGUIZ – Cyrille MARTRAIRE Arolla
Alors, je voulais rencontrer et voir Cyrille Martraire (auteur de Living Documentation et de nombreuses conférences sur l’architecture et le DDD) et le sujet semblait intéressant mais je n’ai pas du tout accroché au duo et au ton humoristique de la présentation. C’est très personnel et cela n’enlève en rien la qualité des speakers et le très bon fond de la présentation.

Les batchs sont dans nos systèmes d’information souvent associés à de mauvais souvenirs. Lents, qui déclenchent les astreintes, avec du code dupliqué, gérés par d’autres équipes. Et pourtant, ils sont toujours présents dans nos architectures modernes.
Dorra et Cyrille proposent de repenser leur architecture et d’appliquer DDD aux batchs pour les améliorer.
Appliquons déjà les bonnes pratiques de nos architectures micro services :
- Identifier des modèles domaines et les isoler
- Ajouter des adapters (REST, Event, Database, …)
- Utiliser du cache (Decorator)
- Pourquoi pas essayer l’Architecture Hexagonale (possible avec Spring Batch Orchestrator)
- Tester (robot launcher + mock/stub/fake/spy)
- Gérer les cas d’erreurs (bloquantes et non bloquantes)
Et l’astuce ultime (que j’adore) est de transformer nos batchs vers une architecture orientée évènements. On passe d’un système en bloc à un flux continu (voir même serverless).
Quelques cas d’usages sont difficiles à gérer avec des évènements mais Cyrille parle de Techniques de Ponctuation (inclure des métadonnées pour indiquer les groupes).
Quelques sources https://gist.github.com/cyriux/62a01433c2d6113554b37cb7f07ffe3d
https://www.youtube.com/watch?v=_x-z2AwkOFI
Conclusion
Ces 2 jours furent très riches, autant en tant que speaker que de spectateur. Beaucoup de rencontres, d’énergie, d’idées et ce genre d’évènement fait plaisir après la période COVID. C’était pour moi une première expérience réussie et je reviendrai avec plaisir.
Et merci à tous les organisateurs et au staff, que ce soit pour l’accompagnement en tant que speaker ou pour l’évènement en général.
Retrouvez le programme complet et toutes les conférences sur Youtube.

Derniers commentaires